In dieser Arbeit wird vereinfacht demonstriert, wie ein LLM (Large Language Model) zur flexiblen Generierung von SQL-Abfragen verwendet werden kann. Als Beispiel dient eine einfache Datenbank mit zwei Tabellen. Der Ablauf ist wie folgt:
-
1. Es liegt eine gut strukturierte Datenbankbeschreibung vor.
-
2. Der System-Prompt des LLM enthält ausschließlich die Datenbankbeschreibung (ohne entsprechende Daten) sowie die Anweisung, aus einer verbalen Beschreibung einen für die Datenbank gültigen SQL-Code zu generieren.
-
3. Der generierte SQL-Code wird zurückgegeben und die Abfrage intern im DV-System verarbeitet.
Das Vorgehen wird in den folgenden Abschnitten näher beschrieben.
Datenbankstruktur
Die vereinfachte Datenbank hat zwei Tabellen. Die Tabelle
Kundenstammdaten beinhaltet die
Stammdaten:
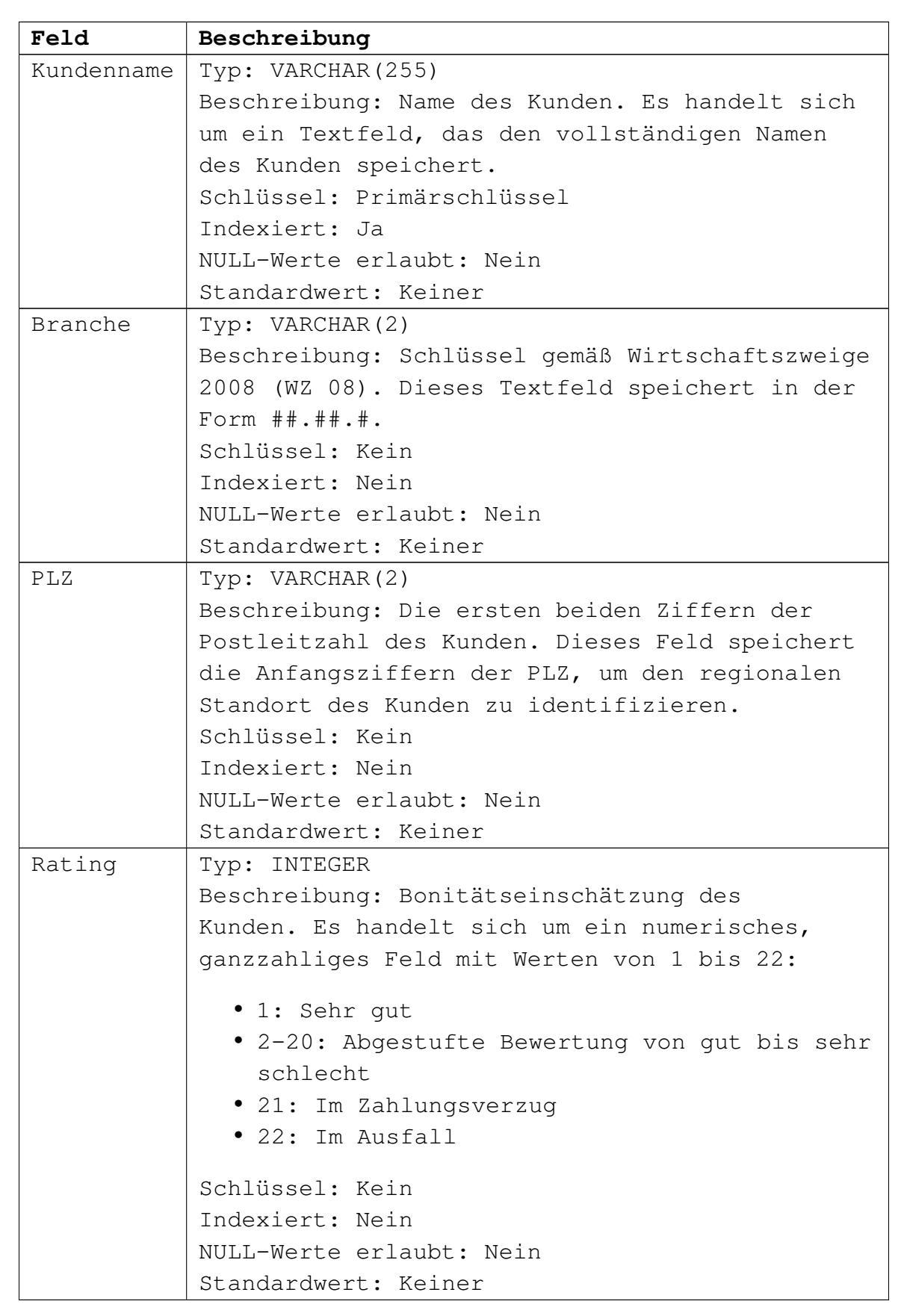
Die zweite Tabelle Transaktionen beinhaltet
die Geschäfte der einzelnen Kunden:
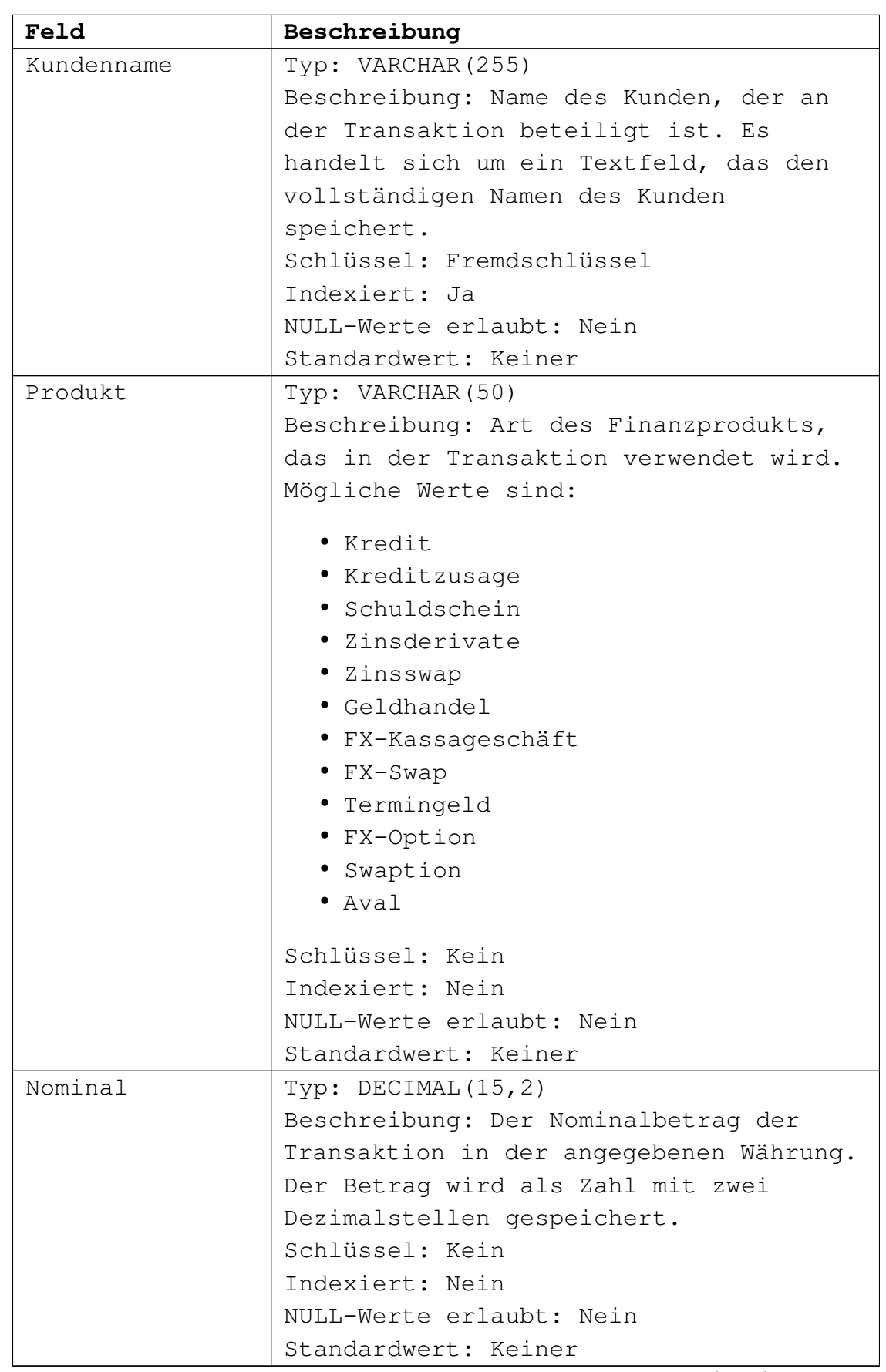
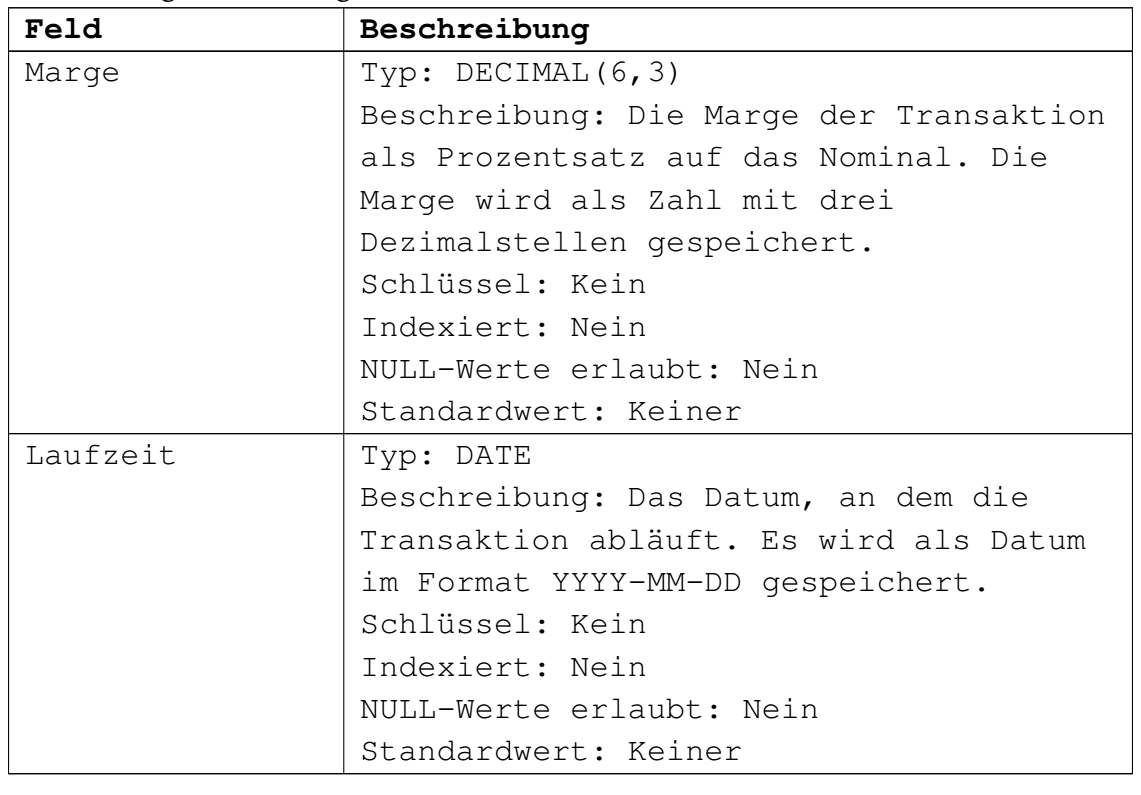
Die Tabellen sind über den Kundennamen verknüpft.
Umsetzung
Als LLM soll beispielsweise ChatGPT benutzt werden. Folgender
Systemprompt wird vorgegeben:
|
Als SQL-Experte hast Du die Datentabellenbeschreibungen
{ |
Im nachfolgenden Python-Code ist der Systemprompt in der Datei
systemP.txt abgelegt, die Datenanfrage ist in der Datei Anfrage.txt.
from openai import OpenAI
input_folder = "C:/Daten"
client = OpenAI()
with open(f"{input_folder}/systemP.txt", 'r', encoding='utf-8') as file:
systemprompt = file.read()
with open(f"{input_folder}/Anfrage.txt", 'r', encoding='utf-8') as file:
frage = file.read()
antwort = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": systemprompt},
{"role": "user", "content": frage}
]
)
sql_query = antwort.choices[0].message.content
print(sql_query)
Selbst dieser einfache Aufbau ermöglicht bereits umfassende Abfragen,
die verbal vorgegeben werden können:
Beispiele
Anfrage:Für den Kunden XYZ bräuchte ich eine Ertragsübersicht nach Derivaten, Kredit und Sonstigen Produkten.
Antwort:
SELECT
CASE
WHEN Produkt IN ('Zinsswap', 'FX-Swap', 'FX-Option', 'Swaption') THEN 'Derivate'
WHEN Produkt = 'Kredit' THEN 'Kredit'
ELSE 'Sonstige Produkte'
END AS Produktkategorie,
SUM(Nominal * Marge / 100) AS Ertrag
FROM
Transaktionen
WHERE
Kundenname = 'XYZ'
GROUP BY
Produktkategorie;
oder als weiteres Beispiel:
Anfrage:
Liste alle Zinsderivate mit allen Transaktionsdaten auf, die mit Banken getätigt wurden und in den nächsten 6 Monaten fällig werden.
Antwort:
SELECT
t.Kundenname,
t.Produkt,
t.Nominal,
t.Marge,
t.Laufzeit
FROM
Transaktionen t
JOIN
Kundenstammdaten k ON t.Kundenname = k.Kundenname
WHERE
k.Branche LIKE '64%'
AND t.Produkt IN ('Zinsswap', 'FX-Swap', 'FX-Option', 'Swaption')
AND t.Laufzeit BETWEEN CURDATE() AND DATE_ADD(CURDATE(), INTERVAL 6 MONTH);
Das SQL-Ergebnis kann nun intern in den entsprechenden Datenbanken verarbeitet und die entsprechenden Datensätze ausgegeben werden. Zu keiner Zeit ist ein Zugriff des LLMs auf die Daten nötig.
Fazit
Die Hauptvorteile von LLMs liegen in ihrer Fähigkeit, Aufgaben zu
automatisieren, Muster zu erkennen und komplexe Anfragen zu verarbeiten.
Diese Vorteile kommen jedoch nur zum Tragen, wenn die zugrunde liegenden
Daten klar und strukturiert sind. Ein gut organisierter Datenbestand
ermöglicht es dem Modell, effizient zu arbeiten und maximalen Nutzen zu
bieten.
Komplexe oder schlecht dokumentierte Daten können zu Verwirrung
und ineffizienter Verarbeitung führen. Das Modell könnte Schwierigkeiten
haben, relevante Informationen zu extrahieren und korrekt zu
interpretieren, was die Komplexität eher erhöht und den Nutzen
mindert.
Es müssen nicht immer Daten weitergegeben werden, um LLMs
sinnvoll zu nutzen. Die Struktur der Daten hat genügend Informationen,
um sinnvolle Erleichterungen im Tagesablauf zu erreichen. Vorausgesetzt,
sie sind klar und präzise definiert. Auf Letzterem sollte der primäre
Fokus innerhalb eines Unternehmens sein.