Motivation: KI und Arbeitserleichterung
Hier soll vereinfacht eine Mensch-Daten-Schnittstelle mit Hilfe eines Sprachmodells dargestellt werden. Dabei kann auf die bereits verfügabren LLMs wie ChatGPT und Gemini zurück gegriffen werden, ohne die Vertraulichkeit der Daten zu gefährden. Es ist somit kein mühsamer Aufbau und Trainings eines eigenen Sprachmodells nötig.
Hier ist eine beispielhafte Case Sudy mit einfachem Prototyp zu einer solchen Schnittstelle.
Beispiel
Die mit 25 Berufsjahren sehr erfahrene WP Erna möchte als Prüfungsleiterin eines Kreditinstituts das Kreditbuch prüfen. Sie bekommt einen Zugang zur Datenbank und eine Beschreibung der Variablen.
Erna ist Wirtschaftprüferin und keine Datenbankexpertin. Die Datenbanken werden zudem aufgrund der Datenfülle immer komplexer. Den überwiegenden Teil ihrer Zeit verbringt Erna damit, die für ihre Analysen notwendigen Daten zu besorgen. Das ist nicht nur ineffizient, sondern auch frustrierend.
Eine Möglichkeit ist, Erna eine Mensch-Maschine-Schnittstelle bereitzustellen. Diese soll die Datenerfordernisse von Erna sprachlich aufnehmen und in einen ausführbaren SQL-Code umwandeln, der anschließend isoliert vom Sprachmodell auf der entsprechenden Datenbank ausgeführt wird.
Am Ende bekommt Erna aus ihrer verbalen Anfrage, die Daten, die sie benötigt und kann ihre Analysen und Auswertungen durchführen.
Umsetzung
Ein möglicher Prototyp ist in nachfolgendem Schema dargestellt. Dabei handelt es sich um ein Schichtenmodell, d.h. es ermöglicht die Trennung zwischen Datenhaltung, Datenbeschreibung und Einsatz von LLM zur Generierung von ausführbarem SQL-Code sowie Analyse im WP-Unternehmen.
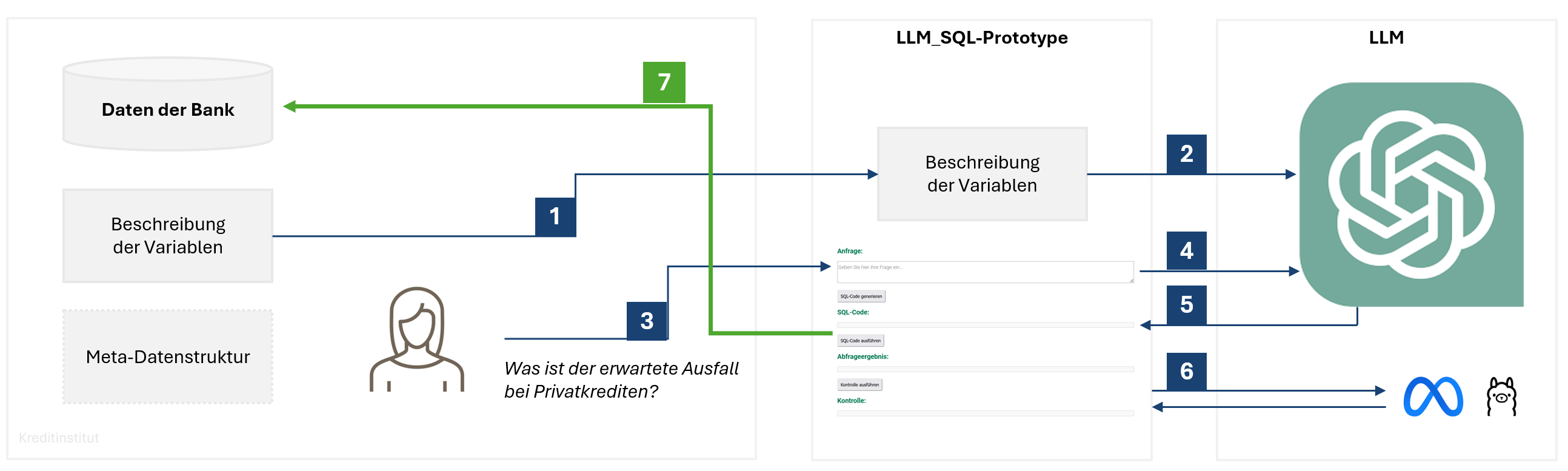
Die Schritte 1 bis 7 sind in diesem Prototyp wie folgt:
-
Die Feldbeschreibung der Datenbank wird dem LLM-SQL-Protoype als File zur Verfügung gestellt.
-
Der Prototype übersetzt die Feldbeschreibung in einen Systemprompt. Im Systemprompt sind auch technisch spezifische Details (z.B. Datenbank-spezifische Besonderheiten des SQL-Codes, um diesen ausführbar zu machen).
-
Die Nutzerin formuliert ihre Frage (z.B. Was ist der erwartete Ausfall bei Privatkrediten?).
-
Der Prototyp ergänzt die Frage um den Systemprompt und schickt sie an das LLM.
-
Das LLM liefert einen ausführbaren SQL-Code an den Prototype zurück.
-
Der Protoype schickt die SQL-Abfrage an ein anderes LLM (z.B. Llama oder Gemini). Der Prompt für die Anfrage ist sinngemäß: "Welche Daten werden mit diesem SQL-Code generiert?". Dies dient der Kontrolle, in wie weit die SQL-Abfrage die Erfordernisse abdeckt.
-
Der Prototype schickt den kontrollierten SQL-Code an die Unternehmensinterne Datenbank. Dort wird der Code ausgeführt und das Ergebnis intern an die Nutzerin weitergegeben.
Vom ganzen Workflow bekommt die Nutzerin nichts mit. Sie formuliert eine verbale Datenanfrage und bekommt nach wenigen Sekunden die relevanten Daten. Nachdem nur der SQL-Code weitergegeben wird, bleiben die Daten stets im Unternehmensnetzwerk